Scattered multidimensional interpolation is one of the most important - and hard to solve - practical problems. Another important problem is scattered fitting with smoothing, which differs from interpolation by presence of noise in the data and need for controlled smoothing.
Very often you just can't sample function at regular grid. For example, when you sample geospatial data, you can't allocate measurement points as you wish - some places at this planet are hard to reach. However, you may have many irregularly located points with known function values. Such irregular grid may have structure, points may follow some pattern - but it is not rectangular, and it makes impossible to apply two classic interpolation methods (2D/3D splines and polynomials).
ALGLIB package offers you two versions of improved RBF algorithm. ALGLIB implementation of RBF's uses compact (Gaussian) basis functions and many tricks to improve speed, convergence and precision: sparse matrices, preconditioning, fast iterative solver, multiscale models. It results in two distinguishing features of ALGLIB RBF's. First, N·log(N) time complexity - orders of magnitude faster than that of closest competitors. Second, very high accuracy, which is impossible to achieve with traditional algorithms, which start to lose accuracy even with moderate R. Algorithms implemented in ALGLIB can be used to solve interpolation and fitting problems, work with 2D and 3D data, with scalar or vector functions.
Below we assume that reader is familiar with basic ideas of the RBF interpolation. If you haven't used RBF models before, we recommend you introductory article, which studies basic concepts of RBF models and shows some examples.
1 Overview of the ALGLIB RBF's
2 RBF-ML interpolation algorithm
Description
Algorithm tuning
Functions and examples
Comparison with SciPy
3 RBF-QNN interpolation algorithm
4 Conclusion
5 Downloads section
rbf subpackage implements two RBF algorithms, each with its own set of benefits and drawbacks. Both algorithms can be used to solve 2D and 3D problems with purely spatial coordinates (we recommend you to read notes on issues arising when RBF models are used to solve tasks with mixed, spatial and temporal coordinates). Both algorithms can be used to model scalar and vector functions.
First algorithm, RBF-ML, can be used to solve two kinds of problems: interpolation problems and smoothing problems with controllable noise suppression. This algorithm builds multiscale (hierarchical) RBF models. The fact that compact (Gaussian) basis is used allows to achieve O(N·logN) working time, which is orders of magnitude better than O(N3) time (typical for traditional RBF's with dense solvers). Multilayer models allow to: a) use larger radii, which are impossible to use with traditional RBF's; b) reduce numerical errors down to machine precision; c) apply controllable smoothing to data; d) use algorithm both for interpolation and fitting/smoothing. Finally, this algorithm requires minor tuning, but it is robust and won't break in case you've specified too large radius.
The main benefit of the second algorithm, RBF-QNN, is its ability to work without tuning at all - this algorithm uses automatic radius selection. However, it can solve only interpolation problems, can't work with noisy problems, and require uniform distribution of interpolation nodes. Thus, it can be used only with special grids with approximately uniform (although irregular) distribution of points.
RBF-ML algorithm has two primary parameters: initial radius RBase and layers count NLayers. Algorithm builds a hierarchy of models with decreasing radii:
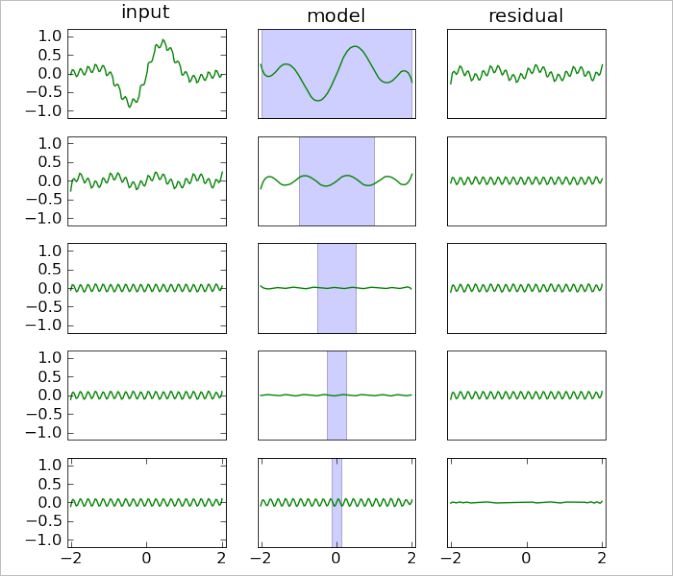
Let's show how our algorithm works on simple 1D interpolation problem. Chart below visualizes model construction for f(x)=exp(-x2)·sin(πt)+0.1·sin(10πt). This function has two components: low-frequency one (first term) and high-frequency one (second term). We build model at interval [-2,+2] using 401 equidistant point and 5-layers RBF model with initial radius RBase=2.
One row of the chart corresponds to one iteration of the algorithm. Input residual is shown at the left, current model is shown in the middle, right column contains output residual ("input residual" - "current model"). Vertical blue bar in the center has width equal to the current RBF radius. Original function can be found at the upper left subchart (input residual for the first iteration).
You may see that at each iteration we build only approximate, inexact models with non-zero residual. Models are inexact because we stop LSQR solver after fixed number of iterations, before solving I-th exactly. However, RBF model becomes more flexible with decrease of basis function radius, and reproduces smaller and smaller features of the original function. For example, low-frequency term was reproduced by two first layers, but high frequency term needed five layers.
Such algorithm has many important features:
RBF-ML algorithm has three tunable parameters: initial radius RBase, number of layers NLayers, regularization coefficient LambdaV.
When you solve interpolation problems, we recommend you to:
If you want to suppress noise in data, you may choose between two ways of smoothing: smoothing by regularization and smoothing by choosing appropriate number of layers. It is better to use both tricks together:
RBF-ML algorithm is provided by rbf subpackage of the Interpolation package. In order to work with this algorithm you can use following functions:
ALGLIB Reference Manual includes several examples on RBF models:
In this section we will study performance of the RBF-ML algorithm and compare it with traditional RBF's implemented in the wide-known SciPy package. Following test problem will be solved:
First test
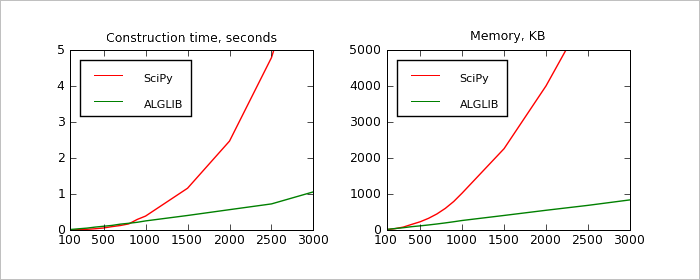
During first test we've solved sequence of problems with RBase=2.0 (moderate radius which gives good precision and robustness) and different N's from [100,3000]. Results can be seen on chart above. We've compared two metrics: model construction time (seconds) and memory usage (KB). Our results allows us to conclude, that:
It is important that results above were calculated for one specific radius - RBase=2.0. Below we'll study performance metrics for different values of RBase given fixed N.
Second test
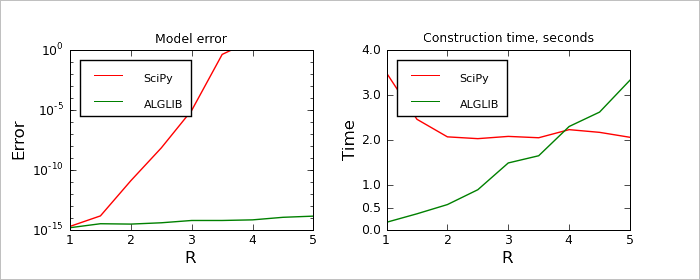
During second test we solved a sequence of problems with fixed N=2000 and different radii from [1.0,5.0]. We used two performance metrics to compare algorithms: 1) model error at the nodes (difference from desired values, which should be fitted exactly) and 2) model construction time. Problems with large radius are hard to solve for both algorithms, but SciPy and ALGLIB face different issues. SciPy implementation of RBF's have problems with ill-conditioning of the linear system, it can't find RBF coefficients with desired precision. ALGLIB implementation of RBF have no problems with precision, but its performance decreases because number of non-zero coefficients in the sparse matrix grows with growth of R. Looking at the charts above, we can conclude that:
Conclusions
Taking into account information above, we can say that:
Distinguishing feature of the RBF-QNN algorithm is its radius selection rule. Instead of one fixed radius, same for all points, it chooses individual radii as follows: radius for each point is equal to distance to nearest neighbor (NN), multiplied by scale coefficient Q (small number between 1.0 and 2.0). Algorithm builds single-layer model, but uses same tricks as RBF-ML: sparse matrices, fast iterative solver. In order to increase convergence, it uses ACBF-preconditioning (approximate cardinal basis functions), which allows to solve problem in less than 10 iterations of the solver. Actually, most of the time is spent in the preconditioner calculation.
As with RBF-ML, RBF-QNN working time grows as O(N·logN). However, unlike RBF-ML, RBF-QNN can't build multilayer models, can't work with radii larger than 2.0, and can't solve problems in the least squares sense (noisy problems, problems with non-distinct nodes, etc.). Core limitation of the algorithm is that it gives good results only on grids with approximately uniform distribution of nodes. Not necessarily rectangular, but nodes must be separated by approximately equal space, and their distribution must be approximately uniform (without clusters or holes). It limits RBF-QNN algorithm by problems with special grids. From the other side, main benefit of such algorithm is its ability to work without complex tuning - radius is selected automatically, algorithm adapts itself to the density of the grid.
RBF-QNN algorithm is used in the same way as RBF-ML. The only difference is that before building RBF model from sample you have to call rbfsetalgoqnn function, which sets RBF-QNN as model construction algorithm.
We've studied two RBF algorithms - RBF-ML and RBF-QNN.
RBF-ML algorithm is a significant breakthrough in the RBF interpolation. It can solve interpolation and smoothing problems, can work with very large datasets (tens of thousands of points) and radii - so large that other algorithms will refuse to work. The most important feature is its high performance - model construction time for N points grows as O(N·logN). RBF-ML can work with arbitrary distribution of nodes, including badly separated or non-distinct nodes. This algorithm is recommended by us as "default solution" for RBF interpolation.
RBF-QNN algorithm was developed as automatically tunable solution, which can be used on a special kind of problems - problems with grid of approximately uniformly distributed nodes. This algorithm is less universal than RBF-ML, but in many cases it can be more convenient.
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




