The singular value decomposition of MxN matrix A is its representation as A = U W VT, where U is an orthogonal MxM matrix, V - orthogonal NxN matrix. The diagonal elements of matrix W are non-negative numbers in descending order, all off-diagonal elements are zeros.
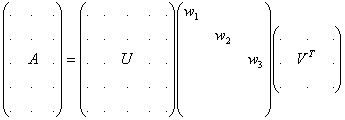
The matrix W consists mainly of zeros, so we only need the first min(M,N) columns (three, in the example above) of matrix U to obtain matrix A. Similarly, only the first min(M,N) rows of matrix VT affect the product. These columns and rows are called left and right singular vectors.
The singular value decomposition has many useful properties. For example, it can be used to: solve underdetermined and overdetermined systems of linear equations, matrix inversion and pseudoinversion, matrix condition number calculation, vector system orthogonalization and orthogonal complement calculation.
The Jacobi algorithm was one of the first to perform the singular value decomposition. It reduces a rectangular matrix to a diagonal matrix by using a sequence of elementary rotations. The method can find all the singular values with high precision, including very small ones. However its performance was rather low, thus the iterative QR algorithms became more popular.
The basis of the most popular modern singular value decomposition algorithms lies in the matrix reduction to a bidiagonal form by orthogonal transformation (this problem is sufficiently simple and requires a finite number of operations to solve it) and its diagonalization by using an iterative QR algorithm. Usually, algorithms differ only by their QR algorithm implementation. At first, the algorithm family based on the Golub-Kahan-Reinsch algorithm was the most wide spread. It is this very same method that was implemented in LINPACK/EISPACK. The advantages of the method are its simplicity and compactness (300 lines of code). Unfortunately, it has no other advantages. Although this algorithm is capable of solving the problems, its convergence and precision are somewhat poor.
There are two singular value decomposition algorithms in the LAPACK library which eliminate the defects of the LINPACK algorithm. The first algorithm (xBDSQR and xGESVD subroutines), which was a prototype for an algorithm described here, has better precision and convergence than its LINPACK analog, so it replaces its predecessor.
It should be noted that the new algorithm finds small singular values of a bidiagonal matrix with better precision. The LINPACK variant of the QR iteration finds all the singular values with the same absolute error. The biggest singular value is obtained with an accuracy close to machine precision. It is sufficient for problems where the absolute error of singular values is critical: when solving systems of linear equations, inverting matrices, etc. But sometimes smaller singular values are important, whose relative error appears to be too large. For instance, if the first singular value equals 1 and was found with absolute error 10-15 (15 significant digits), the singular value which is equal to 10-10 found with the same absolute error will have only 5 significant digits. The new algorithms find all the values with the same relative error, so that both singular values will have 15 significant digits.
Unfortunately, the errors of reducing a general matrix to bidiagonal form brings this advantage to nothing - they corrupt small singular values which can be found precisely by using the new algorithm. Therefore, if your matrix isn't bidiagonal, you will get the only advantage of a new algorithm - better convergence. However, some matrix types could be reduced to bidiagonal form without changing small singular values. Such algorithms are not presented on the site at the moment. If small singular values precision is critical, it is worth finding theoretical material and implementing it by yourself. There are few algorithms designed in this field (hopefully this will change for the better).
As stated above, there are two singular value decomposition algorithms in the LAPACK library. The second algorithm (which is the "divide-and-conquer" algorithm) divides a task of big bidiagonal matrix SVD decomposition into some smaller tasks which are solved by using the QR algorithm. This algorithm shows better performance than the QR algorithm when working with big matrices. For instance, the square matrix singular value decomposition by "divide-and-conquer" when N=100 is 2-4 times faster than by a simple QR algorithm (including the time required to reduce the matrix to bidiagonal form), and is 6-7 times faster when N=1000. However, this algorithm is technically too complex, so it is unlikely to be included in the ALGLIB library in the near future. If the performance of big matrices singular value decomposition is critical to your tasks, please refer to the LAPACK library.
As described above, the modern singular decomposition algorithms reduce the matrix to bidiagonal form and then diagonalize it using QR algorithm. This simple method is quite efficient, but we can speed up an algorithm significantly. The improved algorithm scheme described below was borrowed from the LAPACK library (xGESVD subroutine).
This algorithm works well for square and close to square matrices. If the source matrix is rectangular and has a prolate form, instead of reducing it to bidiagonal form, we can use the LQ or QR decomposition (depending on which matrix dimension is bigger) to represent it as the product of a rectangular orthogonal matrix Q and square (upper or lower triangular) matrix. After that, we will diagonalize the square matrix which is much smaller than the source matrix. Depending on the rows and columns ratio, we can get an algorithm which is 2-6 times faster than the generic algorithm.
The second (more technical) improvement is the optimization of the matrix U calculation. When calculating matrix U, column operations are performed. They are not effective (compared to processor cache usage) when working with ordinary ways of storing matrices by rows, which is typical of most programming languages. If additional memory is available, we can calculate the matrix UT by performing operations with matrix rows. This is more effective especially if the matrix U is large. After that, we can transpose matrix UT.
Both these improvements require additional memory. If it is impossible to allocate enough memory, the programmer can prohibit the use of additional memory, but this will slow down an algorithm by several times.
The RMatrixSVD subroutine performs the SVD decomposition of a rectangular MxN matrix. It returns singular values array in descending order and, if needed, matrices U and VT. In that case, it can return either only left or only right singular vectors and complete MxM or NxN matrices (depending on the values of the parameters UNeeded and VTNeeded). Note that VT contains the matrix VT.
The subroutine parameters are described in more detail in the program comments.
This algorithm is transferred from the LAPACK library.
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




