Cluster analysis is a task of partitioning set of N objects into several subsets/clusters in such a way that objects in the same cluster are similar to each other. ALGLIB package includes several clustering algorithms in several programming languages, including our dual licensed (open source and commercial) flagship products:
Our implementation of clustering algorithms is highly optimized and feature rich (see below for more complete discussion):
1 Agglomerative hierarchical clustering
General information
Metric types
Linkage types
Examples
Performance and multi-core support
2 k-means clustering
General information
Examples
3 Downloads section
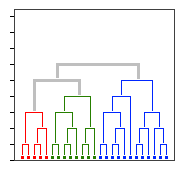
Agglomerative hierarchical clustering (AHC) is a popular clustering algorithm which sequentially combines smaller clusters into larger ones until we have one big cluster which includes all points/objects.
Problem statement includes set of points/objects; metric (formula which is used to determine distance between two points); linkage type (formula which is used to determine distance between two clusters).
We start from N single-point clusters and, according to chosen linkage type, we choose two closest clusters and merge them into one larger cluster. Previous step is repeated until all clusters are merged into one big cluster. As result, we get dendrogram which can be used to quickly get top K clusters for any given K.
Benefits of such approach to clustering are:
Drawbacks are are:
Agglomerative hierarchical clustering algorithm may work with many different metric types. Following metrics are supported:
Metric is chosen during addition of the dataset with clusterizersetpoints. You may also work with dataset specified by distance matrix - without explicitly specifying points and metric. In the latter case you should use clusterizersetdistances function to specify your dataset.
Metric is a formula which defines distance between two points. But we also need some formula to determine distance between two clusters A and B, each of them having several points.
Formula which defines distance between clusters is called "linkage type", and algorithm results are greatly influenced by chosen linkage type. ALGLIB supports several linkage types:
By default, complete linkage is used because it gives best results (robustness, quality of the clusters).
ALGLIB Reference Manual includes several examples on AHC:
In this section we compare performance of two ALGLIB editions - Free and Commercial. All tests were performed on six-core AMD Phenom II X6 CPU running at 3.1 GHz, with one core left unused to leave system responsive. Following products were compared:
During testing we compare running times for different computational cores on two kinds of problems. Algorithm running time is a sum of two terms: time to build distance matrix and time to form clusters. For a problem with N points, each of them having M features, first stage (distance matrix) needs O(M·N2) time, and second one needs O(M2) time. Second stage can be parallelized, while the second one is inherently sequential. Charts below show algorithm total running time and separate times for first and second stages.
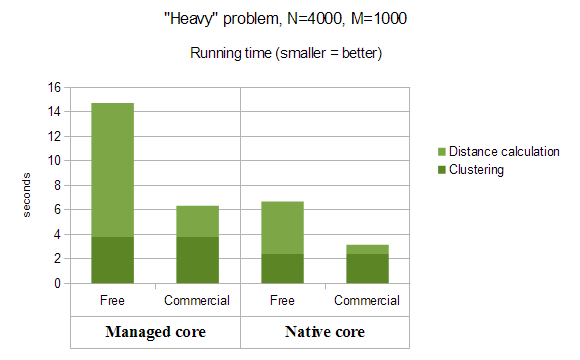
First benchmark was performed on random clustering problem with N=4000 points and M=1000 features, and Euclidean metric. We called this problem "heavy" because it has many features (M=1000), and running time was dominated by distance matrix calculation - it takes 75% of CPU time, and only 25% were used for the clustering itself.
You may see that Commercial Edition of ALGLIB do its best on this problem: we have more than 2x speed-up from going multithreaded (from Free Edition to Commercial one) for both kinds of computational cores - managed and native. And if you work in C#, you may get additional 2x speedup from moving to native computational core, which is present only in Commercial Edition of ALGLIB for C#, which results in 4-5x overall increase in speed.
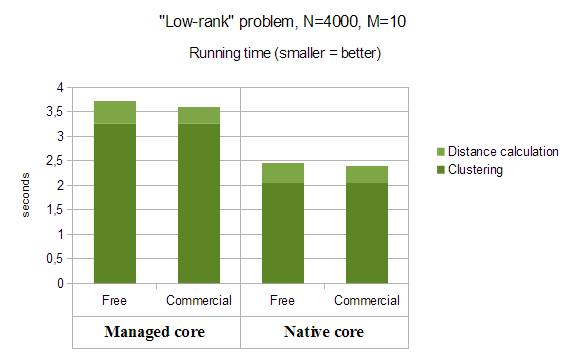
Second benchmark was performed on so called "low rank" problem with large amount of points (N=4000), but just 10 features. On this problem only 15% of the algorithm running time was spent in distance calculation, and 85% of time was spent in the clustering phase, which is inherently sequential.
You may see that on clustering problems with small amount of variables you will get almost negligible speedup from multithreading or other straightforward optimizations. For each of the computational cores, Free Edition performs almost equally as well as Commercial one. However, if you use Commercial Edition of ALGLIB for C#, you may switch from managed core to native one and get about 30% speedup.
K-means clustering is another popular clustering algorithm. Despite being quite old, it is still widely used for solution of large-scale clustering problems.
Short description of algorithm is given below:
Benefits of the k-means algorithm are:
However, this algorithm has following drawbacks:
ALGLIB Reference Manual includes following examples on k-means algorithm:
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




