The Principal Component Analysis (also known as PCA) is a popular dimensionality reduction method. ALGLIB package includes highly optimized PCA implementation available in several programming languages, including:
Our implementation of PCA:
1 Getting started
2 Benchmarks
Comparing complete, truncated and sparse PCA
Comparing C#, C++ and HPC implementations
3 Downloads section
PCA functionality in ALGLIB is provided by the pca subpackage of ALGLIB package. Depending on specific task being solved, you may want one of the following functions:
These functions return orthogonal basis (either K-dimensional or truncated one).
Complete principal component analysis algorithm performs dense singular value decomposition of the entire MxN input matrix (here M is a number of dataset records, N is a number of variables). Singular value decomposition cost is O(M·N2) which is often prohibitively large. Truncated version of the PCA algorithm uses subspace eigensolver which can extract k leading eigenvalues. Cost of one truncated PCA iteration is O(M·N·k); typically just 10 or 20 iterations are required. It is also possible to utilize sparsity of the dataset matrix.
In our first benchmark we will compare complete, dense truncated and sparse trunctated principal component analysis using dense 10000x1000 problem (10000 points, 1000 variables), with truncated PCA being configured to extract top 10 principal components. Fill factor of the sparse matrix is 1%. We used HPC edition of ALGLIB 3.14 (SIMD kernels, multithreading) running at 3.5 GHz Intel CPU for comparison.
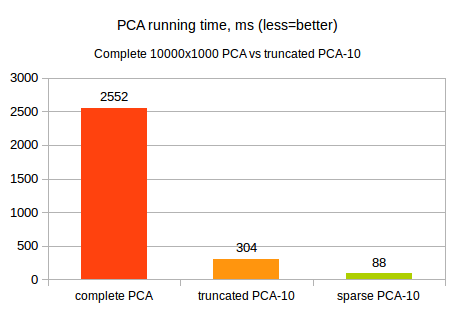
As you may see, switching to truncated version results in roughly 8x increase in performance. And sparsity support adds additional 3x multiplicative speed-up! However, we should note that specific value of the performance gain heavily depends on the problem metrics: dataset size, distribution of the eigenvalues, number of the principal components being extracted.
Both versions of the PCA algorithm (full and truncated) heavily depend on the underlying linear algebra code. ALGLIB has several different implementations of linear algebra functionality (and PCA), all with 100% identical APIs, but different performance:
Our comparison involves single-threaded truncated PCA of 5000x500 dataset with top 10 principal components being extracted. This test was performed ALGLIB 3.14 running on 3.5 GHz Intel CPU running Linux operating system.
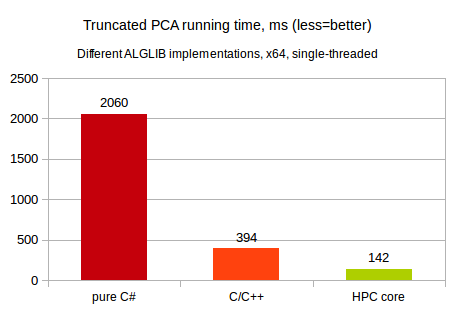
As you may see, unmanaged code is orders of magnitude faster than the managed one. And HPC edition with its SIMD kernels made by Intel is significantly faster than our open source implementation of the linear algebra.
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




