k-means clustering (and its improved version, k-means++) is a widely used clustering method. ALGLIB package includes algorithmically and low-level optimized implementation available in several programming languages, including:
Our implementation of k-means clustering:
1 Getting started and examples
Getting started
Examples
2 Additional settings
Iteration limit and randomized restarts
Choosing initialization algorithm
3 Benchmarks
Comparing C# and C++ implementations
4 Downloads section
k-means clustering functionality is provided by the clustering subpackage of ALGLIB package. In order to run k-means (or k-means++) clustering algorithm you should do the following:
clusterizerstate class by means of clusterizercreate function
As result, you will get an instance of kmeansreport class which contains information about clustering results.
Following fields are returned:
ALGLIB Reference Manual includes following examples on k-means algorithm:
K-means algorithm has guaranteed termination/convergence properties: once started from some (not necessarily good) centers, it will gradually decrease energy function until no further improvement is possible. Two points should be noted, though.
First, it is not mandatory to iterate until full convergence. Quite an often you will get good enough centers after 50-100 initial iterations, but refining them in order to extract last 0.1% of the improvement will need 500-1000 iterations. So, it makes sense to put a limit on iteration count.
The second point is that different selections of initial centers may lead to different partitions being returned. Convergence is guaranteed, but it is convergence to the local optimum, not necessarily the best one. So, you may want to restart algorithm several times using different initial centers and to return the best solution found.
Both options (randomized restarts and iteration limit) are supported by ALGLIB. You can tweak these settings by means of clusterizersetkmeanslimits function.
In the previous section we mentioned that choice of initial centers is essential for the convergence of the k-means algorithm. In fact, there exist several center selection algorithms with different properties. ALGLIB support following initialization algorithms:
You can change center selection algorithm used by ALGLIB with clusterizersetkmeansinit method. By default, fast greedy algorithm is used.
ALGLIB includes several implementations of k-means clustering algorithm, all with 100% same API being provided:
It is quite interesting to compare the performance of these implementations. It is often told that performance of C# programs lags behind that of C++ code, but what about specific numbers?
Our comparison involves single-threaded truncated k-means of 3000x3000 randomly generated dataset, with k=10 clusters selected. This test was performed ALGLIB 3.14 running on 3.5 GHz Intel CPU running Linux operating system.
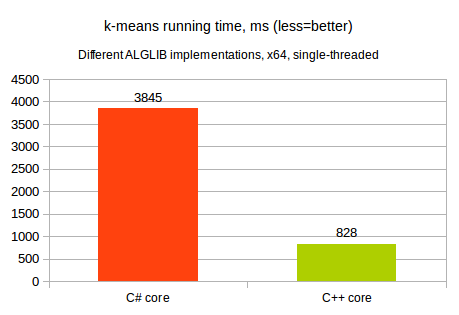
As you may see, unmanaged code is several times faster than the managed one.
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




